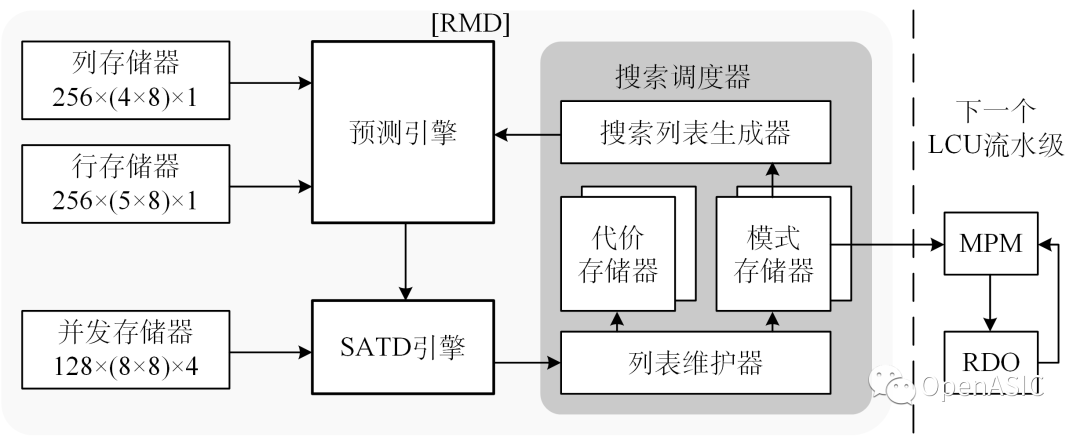
VIP Innovations | A Tightly Coupled AI-ISP Vision Processor
原创 OpenASIC
各位朋友们,我们新开一个专栏,陆续介绍VIP实验室在各大期刊会议上发表的论文和科研工作,还请大家多多关注!
本期介绍复旦大学VIP实验室于2024年发表在IEEE TCSVT期刊的工作,这篇文章的题目为《A Tightly Coupled AI-ISP Vision Processor》。
全文速览
为了实现高质量和高分辨率的图像处理,本工作提出了一种新的视觉处理器,该处理器促进了深度学习增强型图像处理流水线的发展。
• 在系统层面,通过确认分而治之的方法对于协调传统图像处理与图像增强网络至关重要,我们开发了一个紧密耦合的系统,并采用了strip-tile转换数据流,以实现在ISP和深度学习加速器DLA之间进行细粒度低延迟的数据交互。
• 在架构层面,我们设计了21个高效的图像处理模块用于构建传统的ISP流水线、基于tile-based strip layer fusion的DLA,以及一个可编程像素池PPP,支持ISP和DLA的数据访问模式。
• 在软硬件协同设计层面,我们提出了一套综合的优化框架,旨在解决网络实现的开销问题,同时保持图像质量。
• 最后,对AI-ISP视觉处理器的评估显示,EMA访问减少了53.95%,延迟降低了35.51%,且处理器内部SRAM开销极小。高效处理超高清(UHD)分辨率的图像,最高可达每秒168.5帧的吞吐。
Introduction
由于自动驾驶、AR/VR、生物医学设备等领域的快速成长,对高质量图像处理的需求显著增加。ISP在这个演变过程中扮演着关键角色,然而随着应用数量的增长以及光照条件的变化,参数扩展使得调校过程变得更加复杂。ISP通常由数十个模块组成,每个模块具有几十到数千个可调参数,这使得实施一个统一的硬件设计以适应各种应用场景变得非常具有挑战性。
近年来随着深度学习的发展,图像增强网络取得了实质性进展,所提供的图像质量超越了传统图像处理方法。此外,通过在定制的数据集上训练这些网络,可以在多种应用场景中进行优化和应用,而无需大量的手动干预。因此,通过结合传统方法和深度学习方法的优势,将网络与ISP协同集成,为更高效和高质量的图像处理流水线铺平了道路。通用处理器的设计加速分类和检测网络已经得到了广泛研究。
然而,由于图像分辨率限制及其网络结构,图像增强网络的硬件加速通常需要较大的片上内存占用,并涉及大量的外部存储器访问(EMA),这使得通用处理器难以在资源有限的情况下实现实时性能。
此外,先前的研究很少探讨ISP与网络处理器的硬件集成,通常将它们视为片上系统中的独立模块。如图1所示,在ISP完成全帧图像处理后,图像才会被送入处理器进行后处理,这导致了端到端延迟较高。与片外存储器的粗粒度数据交互进一步加剧了EMA问题。
因此,设计一个特定领域的深度学习加速器DLA和更细粒度的数据流对于更高效的图像处理至关重要。
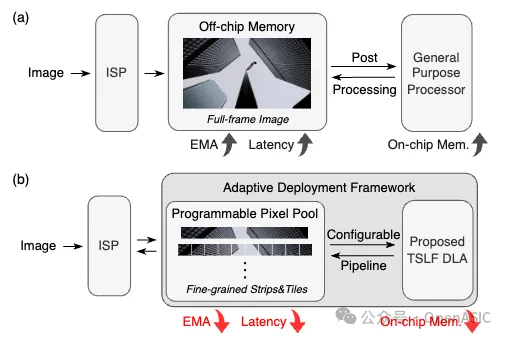
图1
Dataflow And Architecture
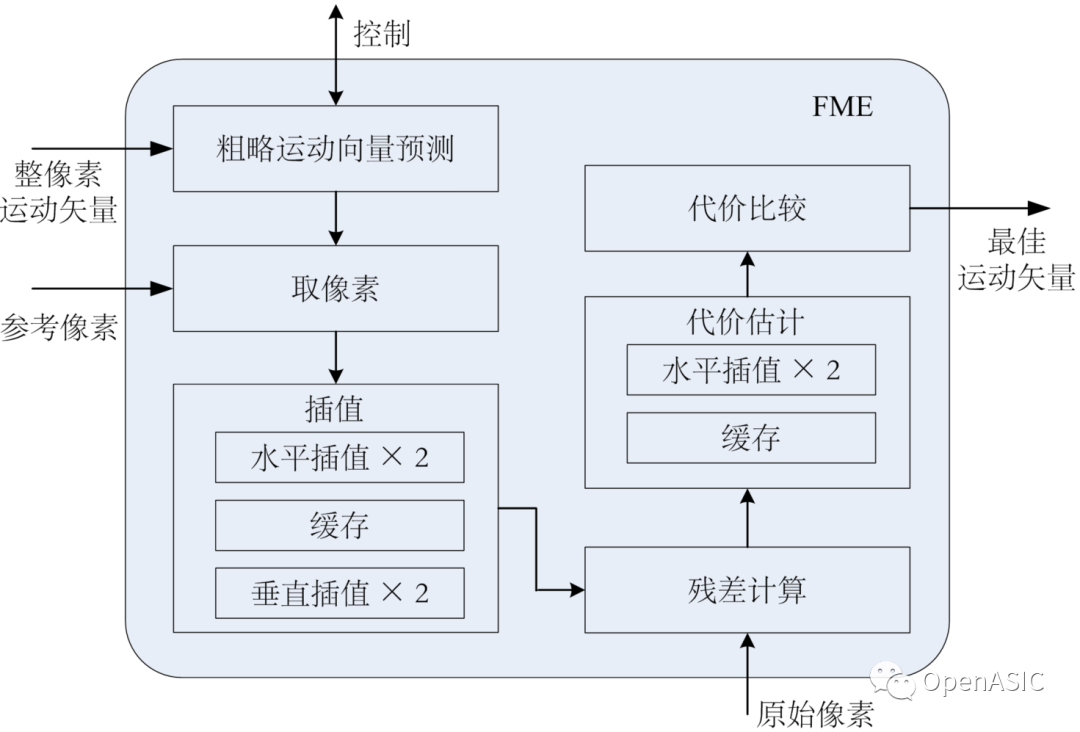
本文所提出的AI-ISP视觉处理器的系统架构,旨在支持深度学习增强型图像处理流水线,如图2中展示。
在这个系统中,ISP的图像处理模块针对经典算法进行了定制化设计,并可以根据具体应用灵活地串联形成子流水线。每个模块主要由一个局部滤波器和line buffer组成。通过移位寄存器对存储在line buffer中的多个图像行执行滑动窗口操作,将数据发送到滤波器中,使用各种经典算法进行处理。
另一方面,开发了基于tile-based strip layer fusion的DLA,以加速多种集成的图像增强网络。另外,构建了一个可编程像素池(PPP),它包含strip buffer组,使得ISP与DLA之间能够实现像素通信,从而达到紧密耦合的集成。为了促进细粒度的片上数据传输,设计了strip-tile转换(STC)数据流。
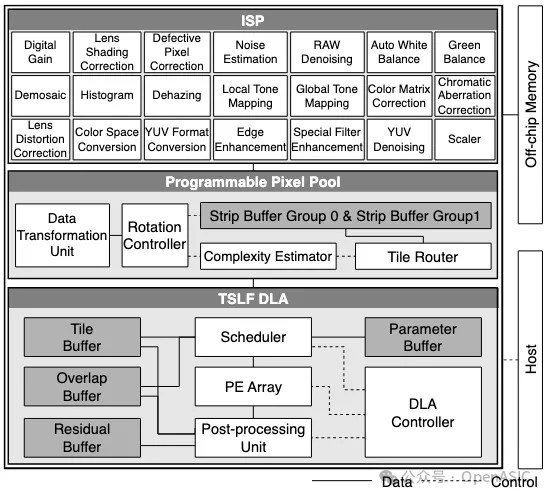
图2
Overview of System Workflow
strip指的是图像的一个片段,其宽度与整个图像的宽度对齐,高度则由设计空间探索所决定。以一个strip为例,图4展示了AI-ISP系统的工作流程。
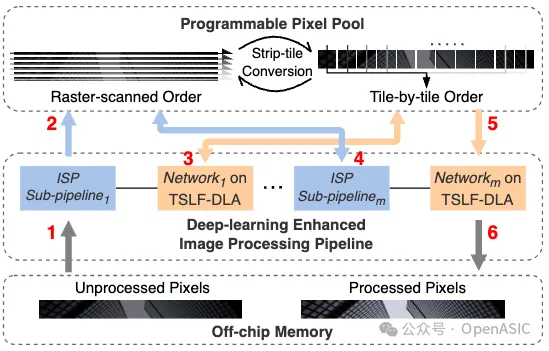
图3
在系统操作之前,未处理的像素存储在片外存储器中。第一个ISP子流水线读取每个strip的像素,进行处理,并将其写入PPP。随后,该strip会依次被送入后续的图像增强网络和ISP子流水线。
在PPP内,执行STC数据流,支持ISP和DLA的不同strip访问模式。当DLA处理strip内的每个tile时,它遵循tile-based strip layer fusion。一旦流水线中的最后一个网络完成其操作,处理后的像素就会被写回到片外存储器。
STC Dataflow and Hardware Mapping
来自ISP的像素流遵循光栅扫描顺序,以行为最细粒度,而DLA则利用特征图tile作为最细粒度来受益于数据局部性。通过利用这些不同的数据访问模式,我们提出了STC数据流。
在部署深度学习增强型图像处理流水线时,STC数据流首先将未处理的光栅扫描像素流组织成一个strip。然后,这个strip从左到右被转换为tile,作为DLA的输入。网络推理完成后,输出的tile被重新转换回strip,并且图像行随后依次送入下游的ISP子流水线。
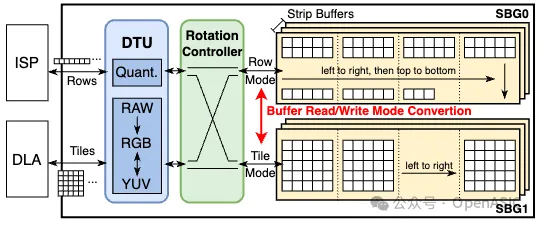
图4
为了提供STC数据流的硬件支持,我们引入了PPP。如图5所示,它由两个strip buffer组(SBG)组成,每个组中的strip buffer数量由图像增强网络的最大输入或输出通道数决定。每个strip buffer存储单通道的数据。
当PPP与ISP进行逐行数据处理交互时,像素流将在其中一个buffer组的多个strip buffer中存储在相同的地址上。同时,DLA采用基于tile的数据处理方式使用另一个buffer组。通过将buffer划分为多个bank并实施不同的地址管理逻辑,可以实现strip buffer的两种数据访问模式。旋转控制器管理strip buffer的读/写模式和数据重用。当ISP和DLA分别完成其对应的SBG中的strip处理后,会发生模式转换,即从ISP向DLA提供strip或相反。
此外,为了解决ISP和DLA之间的数据差异,我们在PPP内部设计了一个数据转换单元(DTU)。该单元负责执行不同位宽的数据量化和反量化,以及促进不同图像格式(如RAW、RGB和YUV)之间的像素级转换。
Tile-based Strip Layer Fusion
先前关于层融合的研究可以分为两种变体:基于line buffer的方法和基于金字塔的方法。如图5(a)(b)所示,在计算输出特征图时,这两种方法都需要存储具有长重用距离的overlap。基于line buffer的方法优先考虑每个tile的向下处理,但这与ISP固有的strip处理优先相矛盾。而基于金字塔的方法则受到累积overlap和tile尺寸的影响,导致显著的存储或重新计算开销。

图5
为了解决这些挑战,我们引入了tile-based strip layer fusion(TSLF),该方法涉及从一个strip中收集的tile,并按顺序进行处理。这种方法与系统级STC数据流的处理顺序一致,同时减少了具有长重用距离的overlap存储负担。
所提出的层融合方法包括两个阶段:strip内处理(intra-strip process)和strip间处理(inter-strip process)。
1. Intra-Strip Process.
在STC数据流中,DLA按照从左到右的顺序处理strip内的每个tile。如图(c)所示,strip内处理的主要目的是最小化tile之间overlap域造成的内存开销。
这种类型的overlap一旦被存储,就可以立即用于后续tile的处理,并且可以被视为具有短重用距离。考虑到基于金字塔的层融合,每一层的输出特征图既包括新生成的特征图,也包括用于下一层计算的overlap部分。相比之下,TSLF仅专注于影响新生成部分的输入特征图。
当获得一个新生成的输出tile时,通过整合之前缓存的overlap列,可以在下一层立即进行输出tile的计算。同时,为每个层存储下一个tile的overlap列。我们使用一个overlap buffer来存储相邻tile之间的overlap。
为了最小化片上内存开销,overlap列的宽度Wcol必须尽可能小。在TSLF中,Wcol值被设置为K−1,这意味着缓存的overlap列宽度仅由当前层的卷积核大小决定。这种方法确保了除最左边和最右边的tile外,每层的输出tile宽度与输入tile相匹配。
尽管包含填充会导致最外层tile的宽度在各层间有所变化,但它们在DLA上的处理流程与常规tile相同,对计算单元的利用率影响微乎其微。
2. Inter-Strip Process.
strip间处理的主要思想是消除相邻strip之间的overlap。如图6(a)所示,对于两个连续的strip,strip(i+1)的计算依赖于在strip(i)推理过程中缓存的所有中间特征图的最后Ky−1行。这种类型的overlap具有长重用距离,可能导致显著的内存开销。为了解决这个问题,TSLF对各个strip执行卷积操作,并在每一层的输入strip的顶部和底部应用填充以避免依赖于overlap。将填充大小P设置为(Ky−1)/2,使得每一层可以直接进行推理,且strip的高度在整个过程中保持一致。
然而,直接处理每个独立的strip然后将它们连接起来会导致边界效应。为了减轻strip连接对图像质量的影响,如图6(b)所示,我们选择引入初始输入strip和网络最终输出strip的共享边界区域和基底区域。需要注意的是,这里的共享边界与层融合中的长重用距离overlap不同。这种边界区域仅出现在网络的输入和输出strip上,对于一个图像增强网络来说,通常包含1个或3个通道。因此,相比中间特征图,网络的存储需求大大减少。
我们采用一种拼接策略来恢复输出特征图。如图6(c)所示,每个strip保留其边界的半部分,然后将这些边界连接在一起。通过这种方法,可以在最小化内存开销的同时,确保strip间的平滑过渡,从而保证图像质量不受影响。
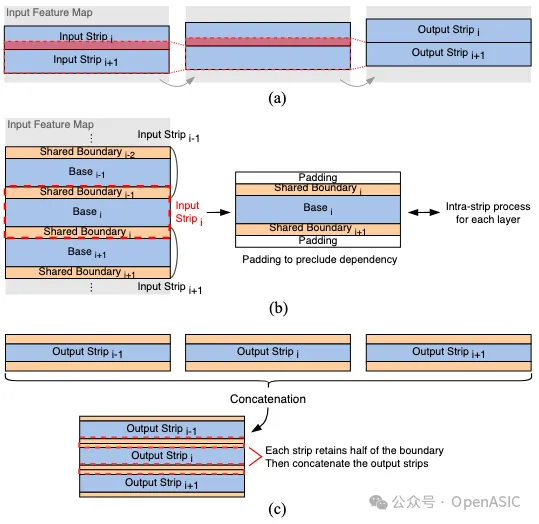
图6
TSLF DLA Architecture

图7
如图7所示,为了支持TSLF,我们设计了一种专用的DLA架构。主机离线编译网络为指令,这些指令包含了层数、操作类型以及每层的维度信息。
控制器从主机接收这些指令,对其进行解码,并向其他模块分发控制信号。通过系统AXI总线实现与主机和片外存储器的数据交互。在预加载指令和网络参数完成后,DLA会在PPP内完成初始STC后启动基于tile的计算。主要计算单元是PE阵列,包含2,048个乘累加器。
根据每个调度,PE阵列对一个输出特征子tile进行并行处理,该子tile宽度为32,高度为4,涉及4个输入通道和4个输出通道。每个PE包含一个乘累加(MAC)单元和寄存器,采用输出静止数据流以减轻图像增强网络推理过程中对特征数据移动的需求。对于输入值为零的计算进行旁路以减少功耗。为了确保高利用率,在每个PE中卷积核的宽高计算在时间维度被展开。
调度器和后处理单元(PPU)提供了对TSLF strip内处理和strip间处理的支持。调度器通过直接内存访问(DMA)从buffer获取特征和权重数据。一个由多路复用器和移位寄存器实现的二维数据移位器将填充和strip内overlap与输入特征tile拼接起来,使得PE阵列可以在迭代中重用数据。完成所有输入通道的迭代后,子tile被发送到PPU。
PPU由多个单元组成,旨在加速网络推理过程中的非卷积操作,包括部分和累积、激活函数、残差累积、量化、上采样和strip间边界处理。采用了融合操作流水线以减少中间数据的存储器访问。当网络中不存在相应的操作时,相关单元可以被旁路。写回逻辑裁剪输出strip的一半共享边界区域,并将结果写回到tile buffer中对应的地址。
Systematic Optimizations
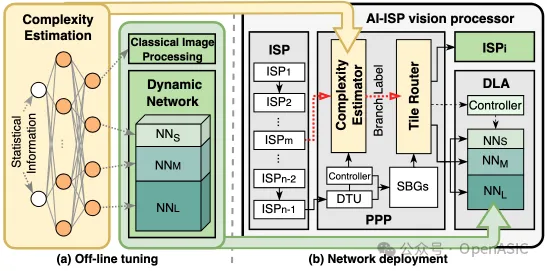
图8
我们开发了一个新颖的图像增强网络部署框架,如图8所示。该框架提供了以下优势:
• (1)遵循STC数据流的固有处理顺序:基于tile的自适应图像增强充分利用了DLA和ISP。通过将部分tile路由到ISP或容量较小的网络中进行处理,此方法显著减少了计算负担,同时保持了整体图像质量。
• (2)与先前工作不同:我们的方法利用来自ISP子流水线的统计信息作为先验知识来估计每个输入tile的复杂度,而不是使用多个卷积层来估计复杂度,从而减少了复杂度评估的开销。
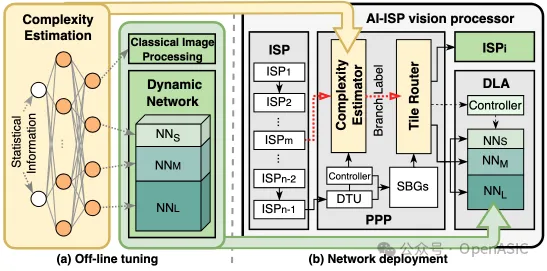
1. 离线调优
基于tile的自适应图像处理包含四个不同的分支:ISP及其对应的三分支动态网络。动态网络由NNS、NNM、NNL组成。这三个网络结构相同,但每层的通道数不同,其中NNL与原始网络相同。这些网络分别使用根据其增强难度级别标注的tile数据集进行了独立训练。为了引导图像tile进入适当的分支,我们设计了一个轻量级的复杂度估算网络。该网络采用简单的全连接层构建,每一层后跟随ReLU激活函数以帮助排序tile复杂度。在系统运行期间,复杂度估算器收集每个图像tile的均值和方差作为网络的输入统计信息。经过计算后生成一个概率向量。
2. 硬件修改与部署
PPP集成了一个复杂度估计模块,用于预测每个tile的分支标签。该模块专门为全连接网络构建,并在运行时加载预训练的权重。由于复杂度估算网络的轻量化特性,该模块能够以最小的硬件开销实现实时分支预测。此外,还设计了router模块,根据tile标签将其导向ISP或DLA进行自适应图像处理。得益于STC数据流,这种基于tile的ISP strip内像素计算不会产生任何额外的存储器访问开销。
Evaluation
TSLF DLA Evaluation
下图9提供了我们提出的TSLF DLA在特征图的EMA和片上内存占用方面的比较分析。
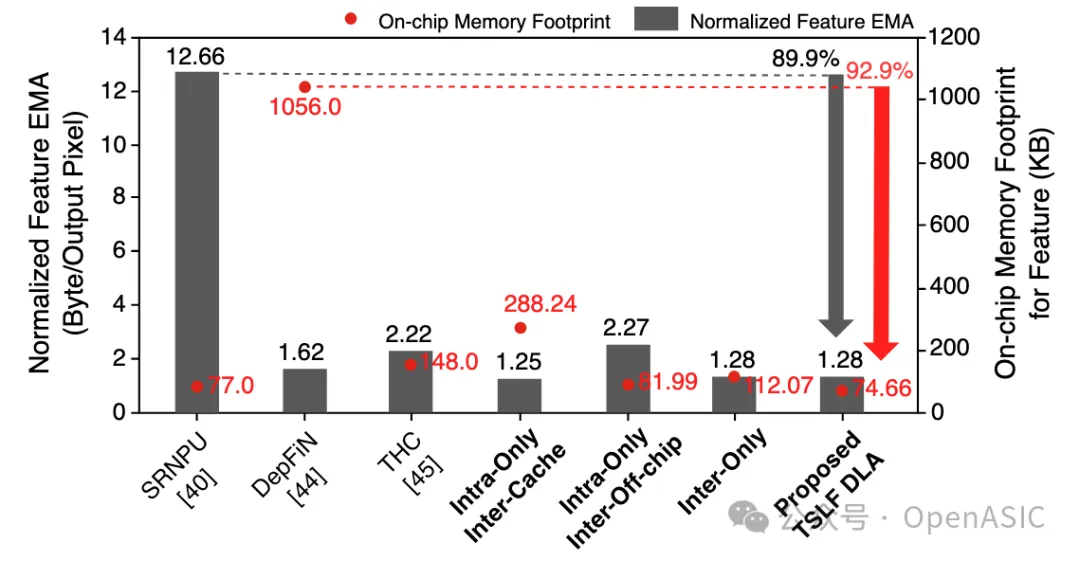
图9
在TSLF DLA中,归一化的EMA为每输出像素1.28字节,相比SRNPU减少了89.9%。片上内存用于存储条带内处理所需的特征图tile和overlap。总容量为74.66 KB的情况下,我们的方法相对于DepFiN减少了92.9%的片上内存占用。
此外,从图9中最后四列可以看出,当仅使用条带内处理时,条带间overlap要么需要更多的片上内存,要么需要存储在片外,导致EMA增加。由于条带间overlap的长重用距离,这种开销随着网络通道数或特征图分辨率的增加变得更加显著。当仅使用条带间处理时,每一层的条带内overlap宽度累积,导致片上内存占用增加。相比之下,同时使用条带间处理和条带内处理的TSLF表现出最少的片上内存占用和EMA。
如表1所示,TSLF DLA在应用、片上内存大小和系统耦合方面优于最先进的图像增强专用加速器。
具体来说,TSLF DLA支持广泛的图像增强网络,并可以无缝集成到各种图像处理场景中。
FPGA和ASIC实现的评估报告分别达到0.74 TOPS和3.28 TOPS的峰值性能。它在800 MHz、0.72V下消耗307 mW功率,峰值能效为10.69 TOPS/W。归一化的逻辑面积效率计算为1.92 TOPS/mm²。
我们的设计在ASIC上以117.3 fps生成UHD分辨率输出,在FPGA上达到26.4 fps。总共分配了119 KB的片上内存来存储特征图tile、overlap、残差和网络参数。
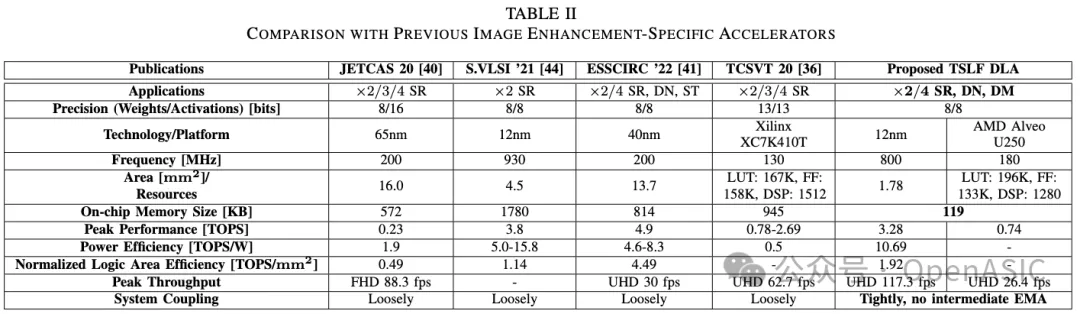
表2
System Level Analysis
为了评估紧耦合AI-ISP的优势,我们在生成单个UHD图像时比较了以下系统配置:
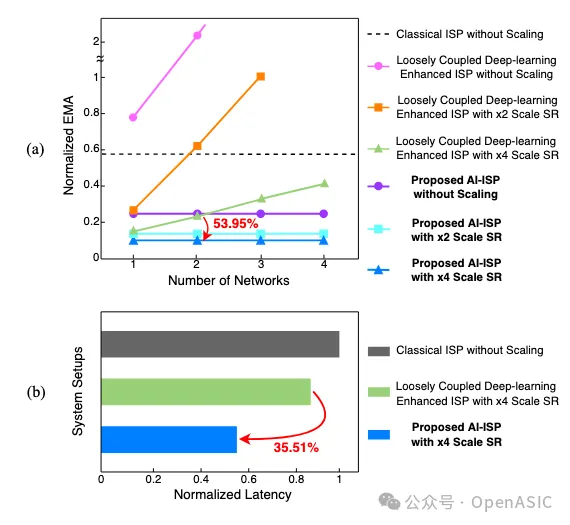
• (1)ISP:直接在原始分辨率图像上进行处理。
• (2)松耦合的深度学习增强型ISP:ISP以全帧粒度与DLA交互,并使用片外存储器进行数据交换。
• (3)我们提出的紧密耦合AI-ISP视觉处理器:利用PPP在ISP和DLA之间执行细粒度的STC数据流。
在我们的分析中,为了符合实际使用场景,SR的输入和输出通道数设置为1,而对于其他图像增强网络,则设置为3。

表2
图3(a)展示了上述系统在集成不同数量网络时所需的EMA对比。尽管SR的应用减少了EMA,但在图像处理流水线中添加更多网络时,松耦合的深度学习增强型ISP表现出显著增加的EMA。相比之下,由于STC数据流和PPP的数据重用,我们的AI-ISP的EMA保持恒定,仅依赖于输入和输出图像的大小,显示出可扩展性。具体来说,通过结合DN-DM网络和×4 SR,AI-ISP相比松耦合版本实现了53.95%的EMA减少。
此外,我们在FPGA实现的不同系统配置下对这些两个网络进行了延迟比较。直接处理UHD输入图像的ISP产生了最长的延迟。通过细粒度的数据交互和分支,AI-ISP比松耦合的深度学习增强型ISP延迟降低了35.51%。
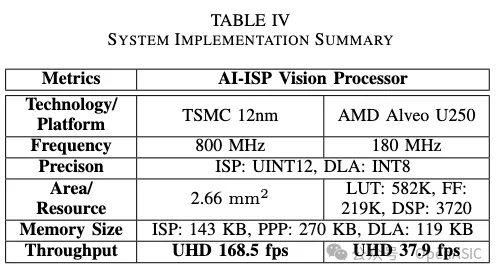
表3
在整合ISP、PPP和TSLF DLA后,使用TSMC 12nm工艺库实现的AI-ISP总面积为2.66 mm²。AI-ISP的吞吐量由具有较高计算复杂度的DLA决定。通过提出的自适应部署框架,进一步减少了DLA上的网络工作负载。基于代表大多数现实场景的DIV2K数据集测试结果,该系统的吞吐量在UHD分辨率下最高可以达到168.5 fps。
关注我们
实验室网站 http://viplab.fudan.edu.cn
微信公众号 OpenASIC
官方网站 www.openasic.org
知乎专栏 http://zhuanlan.zhihu.com/viplab