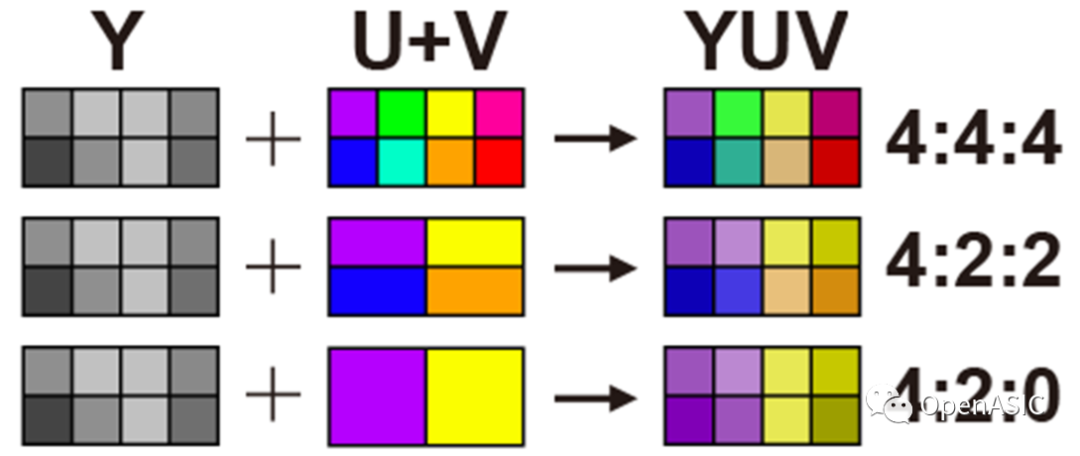
本系列主要介绍视频编解码芯片的设计,以HEVC视频编码标准为基础,简要介绍编解码芯片的整体硬件架构设计以及各核心模块的算法优化与硬件流水线设计。
低码率的视频更利于传输和存储,但失真度会大大增加,相反,低失真度的高质量视频则会使码率增加,增大网络传输的压力。如何在视频码率和编码质量之间权衡是视频编码中永恒的命题,这个过程称之为率失真优化。
本文提出了一种硬件友好的码率估计算法,依次介绍了算法优化和VLSI实现,最后对VLSI实现进行了性能评估。
概述
01
率失真曲线
如下图所示,可操作率失真曲线包络是一个靠近理论曲线的凸包络。率失真优化的目的就是找到一组编码参数使得对应的可操作点尽可能接近率失真曲线理论值,也就是在一组可能的操作点中确定使系统性能最优的操作点。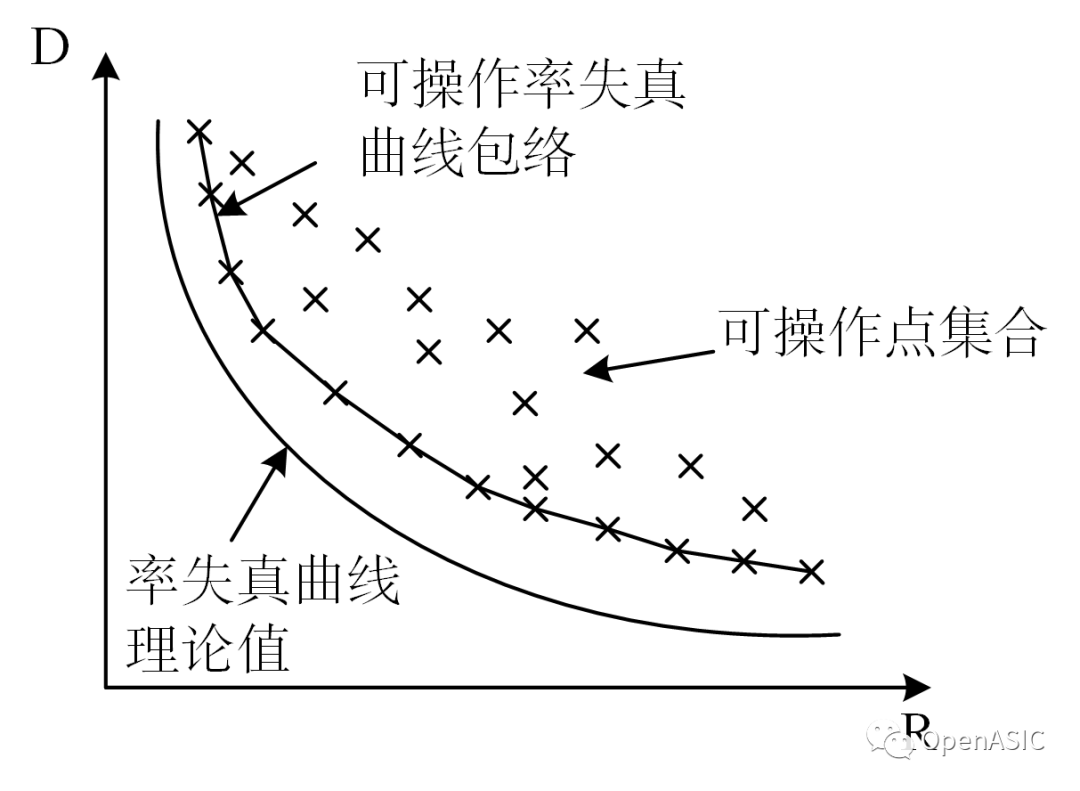
图1
02
设计考量
视频编码过程中,帧内预测和帧间预测的后预测阶段需要计算得到较为精确的失真代价和码率代价。下面给出计算精确RDO代价所需的重建环路数据流图。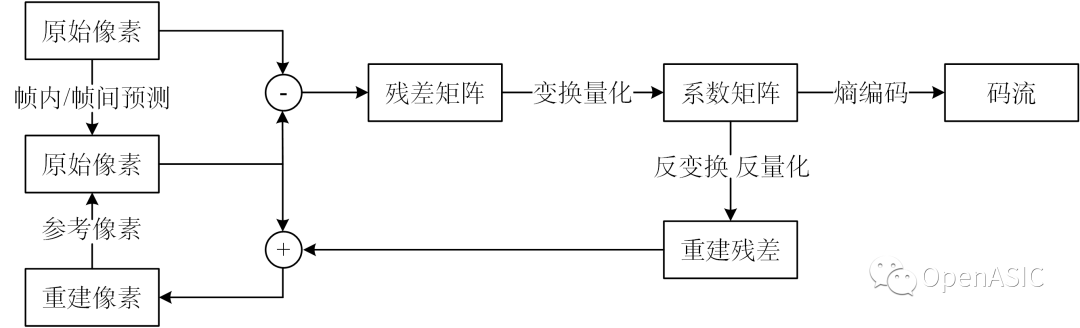
图2
为了保证失真代价的精确度,不可避免地需要计算经过重建环路的重建像素和原始像素的差异代价,这意味着要在RDO模块中引入完整的重建环路,其中存在非常大的硬件资源代价和周期代价。前者主要来源于变换中4×4到32×32尺寸的DCT矩阵乘法,后者则由重建像素和预测像素之间的数据依赖导致。
算法优化
变换单元统计
对于系数编码,尽管CABAC通过引入了上下文去除了大量的信息熵,但是绝大多数情况下码率代价和TU系数之间仍然存在着正相关性,即当TU系数矩阵越复杂时,编码其所需的码流就越多。基于统计的算法,其思路是:通过“某计算”得到能够表征当前TU系数复杂程度的值,再通过“某映射”得到码率代价。
本文采用了“带权重的绝对值之和”作为表征TU系数复杂度的计算方法,计算下式所示。
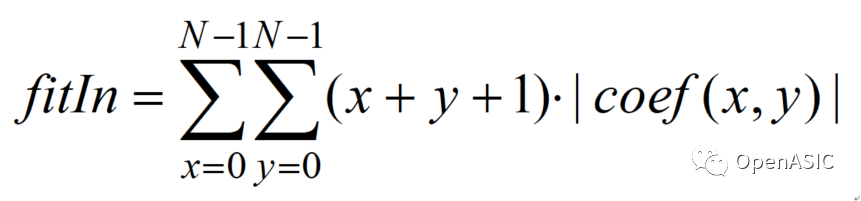
其中x和y为系数在系数矩阵中的横纵坐标,coef为系数矩阵。
确定了拟合输入后,需要获取拟合输出,如下图所示,分别给出了某视频序列给定QP下32×32亮度TU和色度TU的映射情况。
图3
本文利用Matlab对上述数据进行了函数拟合,采用的映射关系如下式所示。
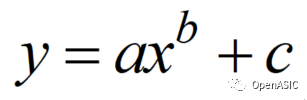
为了进一步实现硬件化,算法做了以下优化:
1)数据定点化,根据数据的实际运算确定其要保留的小数位。
2)映射简化,将上式中的b简化为0.5。
3)x0.5的优化,基于7位查找表、定参数乘法器和移位器实现。
4)𝜆的优化,将𝜆合入拟合参数a和c中,节省一个乘法操作的cycle。
其他信息统计
除了系数矩阵,预测信息和划分信息也经过熵编码输出为码流,需要进行信息统计。
1、预测信息
对于帧内预测,HEVC通过构建MPM候选模式列表,将模式编码转换为Index或Index+Mode的编码,如下表所示。
表1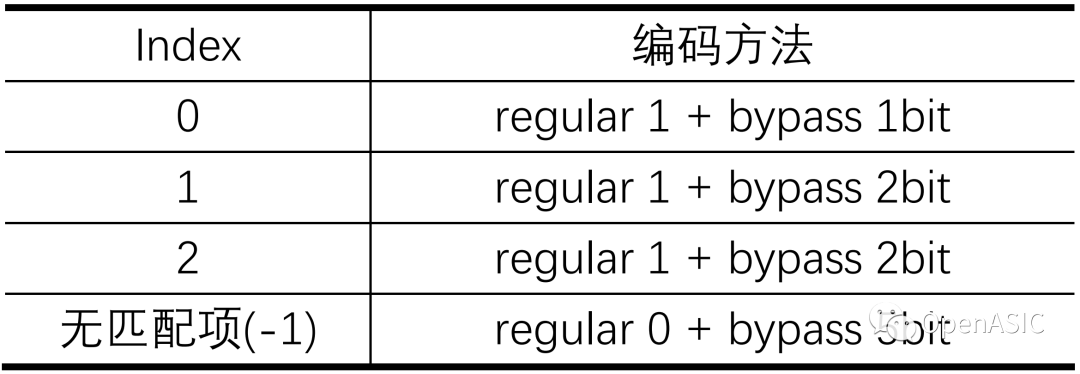
对于帧间预测的非Merge模式,HEVC通过构建AMVP候选MV列表,将MV编码转换为Index+MVD的编码。其中对Index的编码较为简单,如下表所示。
表2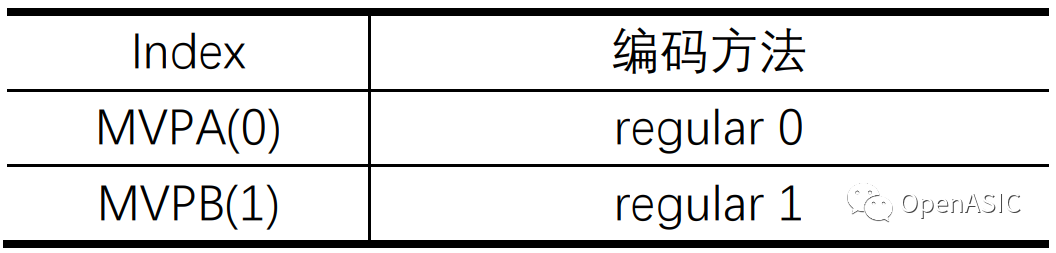
对MVD的码率估计算法较为复杂,MVD的编码和系数矩阵类似,即MVD越大,码率越大。通过下式将二维向量MVD转化为一维标量fitIn。
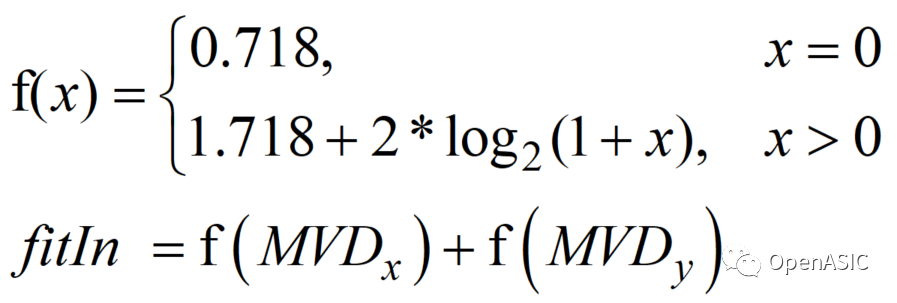
计算fitIn和MVD码率估计结果,如下图所示,其中横轴为fitIn,纵轴为码率估计结果,最终选择 y=ax+b 作为拟合函数。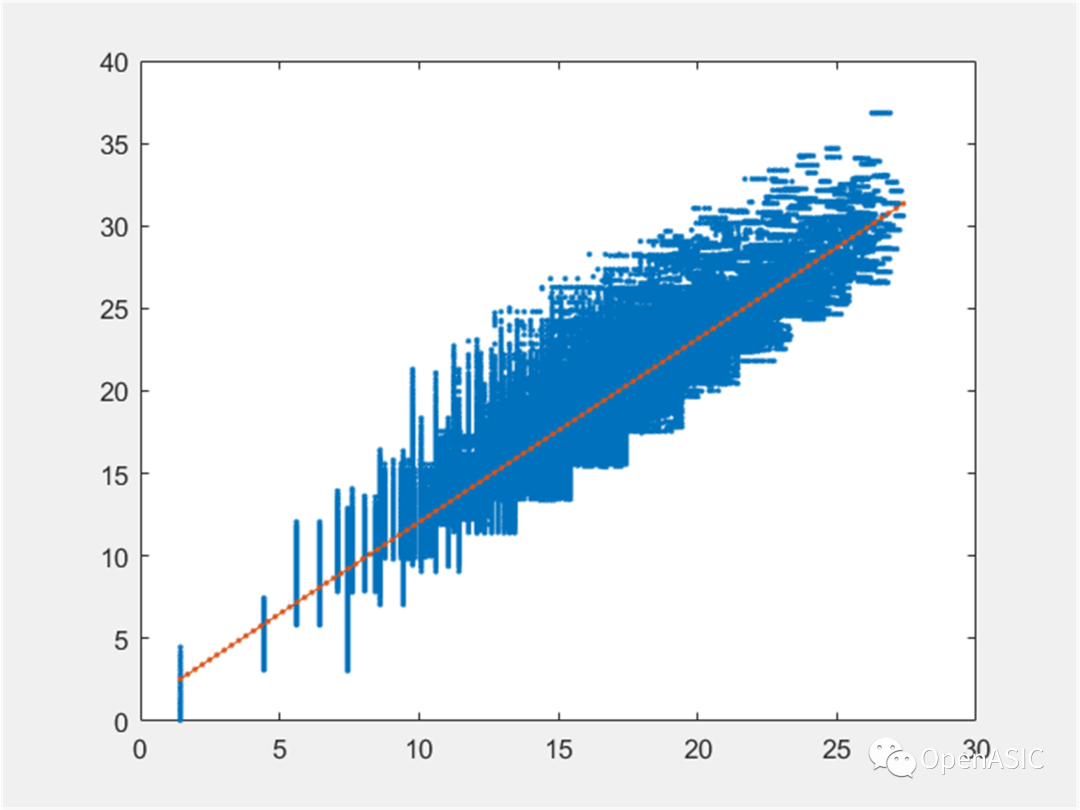
图4
对于帧间预测的Merge模式MV编码,因为MV复用相邻块的MV,故只需要对Merge候选MV列表的Index(0~3)进行编码,如下表所示。
表3
2、划分信息
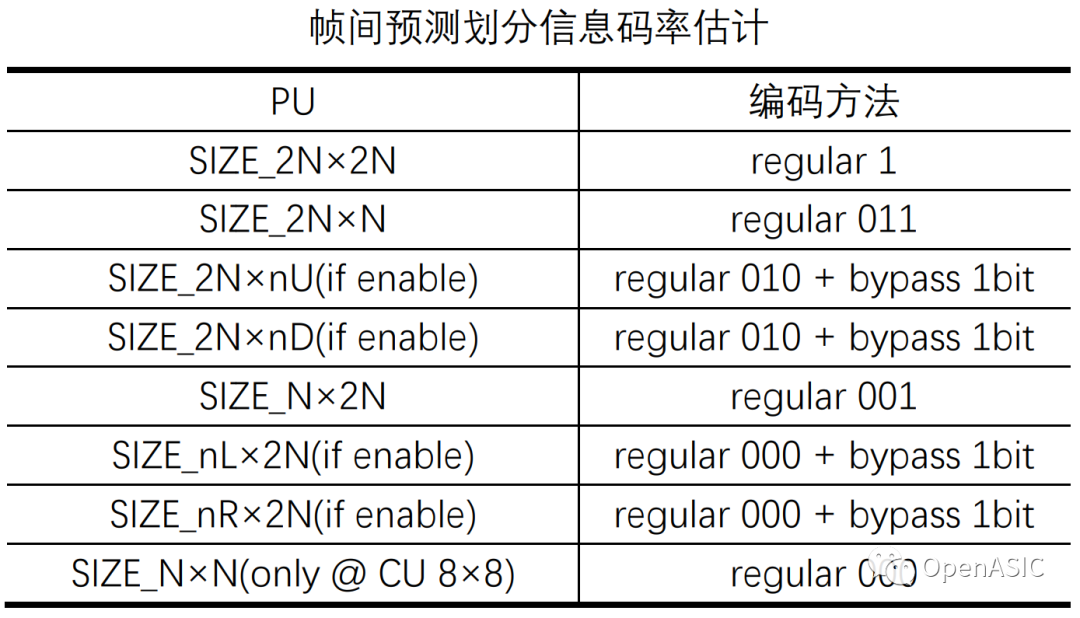
帧内和帧间预测划分信息码率估计如下表所示。
表4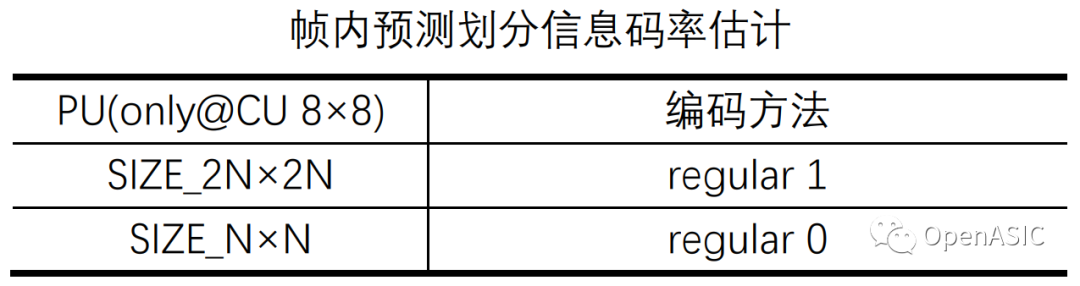
VLSI实现
顶层架构及时序
视频编码中的率失真优化递归并不复杂,硬件实现中可以通过将RDO模块展开为4×4、8×8、16×16、32×32、64×64这5个尺寸的计算模块来提高并行度,只需要在关键节点上保持同步即可。
本文提出的架构如下图所示。其中包括任务发布模块、预测模块、重建环路模块、代价计算模块和模式判决模块。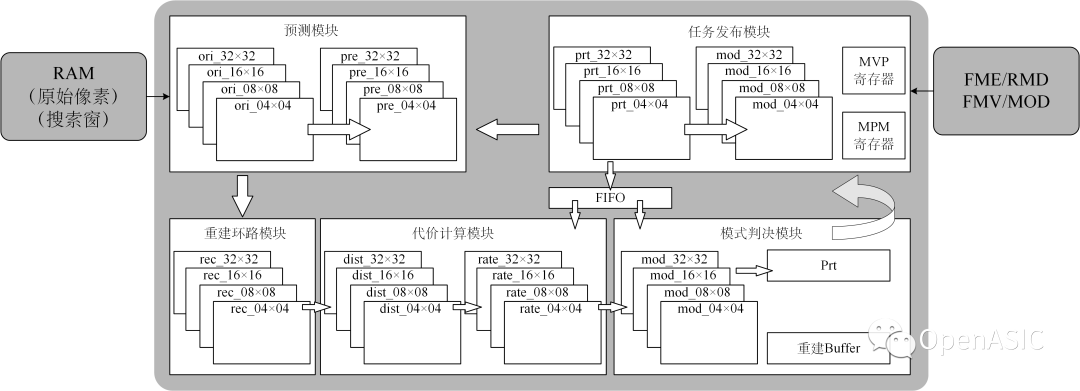
图5
图中的箭头标志数据流向,模式判决模块的反箭头表示存在feedback数据。同一PU的所有待遍历模式之间没有数据依赖,可以流水实现。重建环路中的数据依赖在4×4 PU中体现的最为明显,因此4×4 PU的吞吐率是RDO模块的瓶颈。
任务发布模块
任务发布模块的功能是遍历所有PU,以及对应PU的所有编码方式,即RMD和FME模块传输过来的帧内预测模式信息和帧间预测MV信息。任务发布模块的输入为所有尺寸PU的粗略编码方式,以下统称帧内预测的角度模式和帧间预测的FMV为rough mode。
图6
prt模块中进行不同尺寸PU的Z-scan顺序和色彩通道遍历,输出位置和通道信息去RAM中取数据。mod模块根据读取到的rough mode数据进行当前PU的编码方式遍历。mod模块和prt模块通过握手协议保持一致,在mod遍历完当前PU的rough mode之前,prt模块不会进行下一个PU的遍历。
任务发布模块是RDO过程中唯一的模式信息来源,其本身需要生成后续所有模块中需要的mod类参数,如MVP_idx,MPM_idx等,下称general mode,因此任务发布模块中需要包括LCU级的Mode和MV寄存器阵列。任务发布模块和后续不直接连接的模块如代价计算模块和模式判决模块之间需要FIFO来暂存general mode。
预测模块
预测模块将完成帧内和帧间的预测过程。帧内预测时,预测模块中仅src模块与RAM(原始像素)存在交互,读取原始像素;帧间预测时,src模块和preP模块会与RAM(原始像素)和RAM(参考像素)存在数据交互,读取原始像素和参考像素。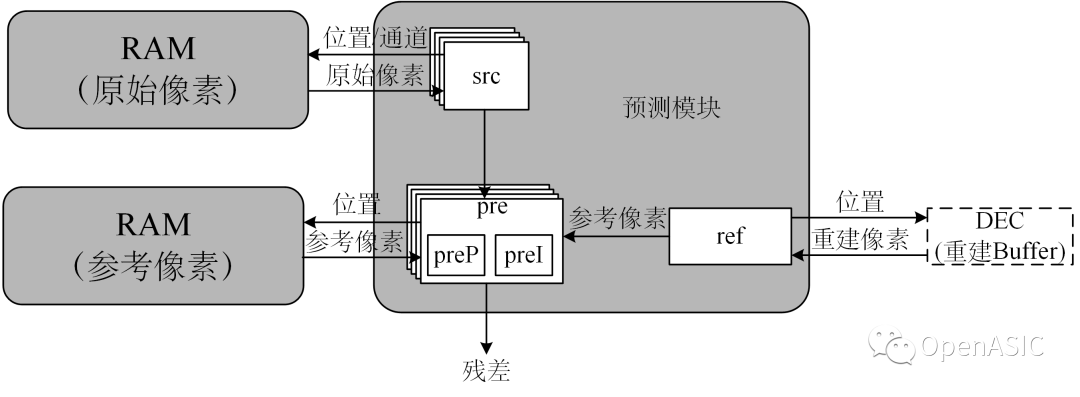
图7
参考像素的准备过程,即ref模块和模式判决模块中buffer rec的数据交互,和原始像素的读取是同时进行的,因此所有尺寸的PU得到预测像素的延时是相同的。帧间预测过程中,参考像素和原始像素通过两组接口在两个RAM中分别读取,因此不同尺寸的PU获取预测像素的延时仍是相同的。
重建环路模块
重建环路模块的设计可参考往期推送——《视频编解码芯片设计原理----07重建环路》,硬件结构如下图所示。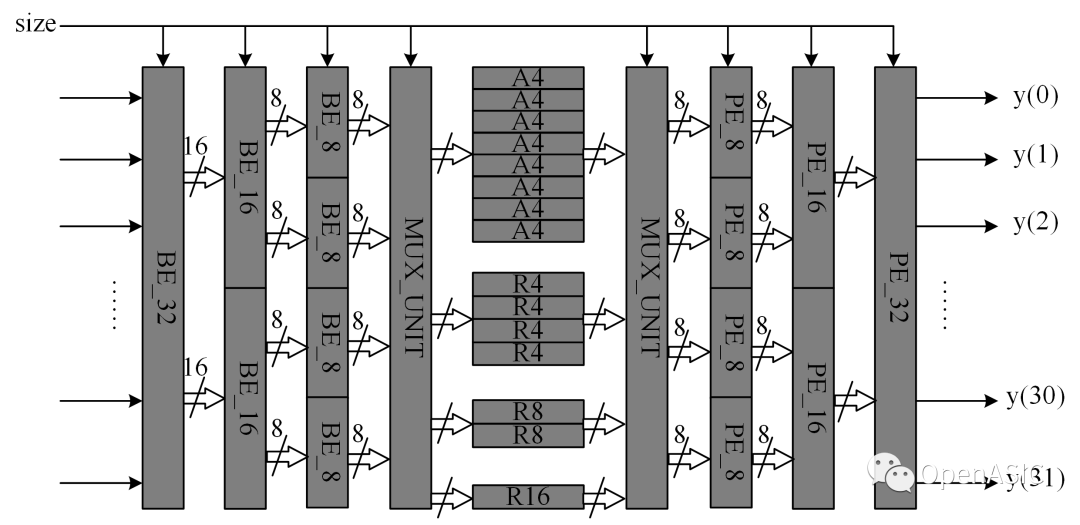
图8
代价计算模块
代价计算模块的功能是计算失真代价和码率代价,下图为PU尺寸4×4和大于4×4两种情况下的代价计算模块时空图。对于4×4块,由于是一次性读完PU所有数据,因此对于失真代价和码率代价的计算是严格的1 cycle和3cycle限制。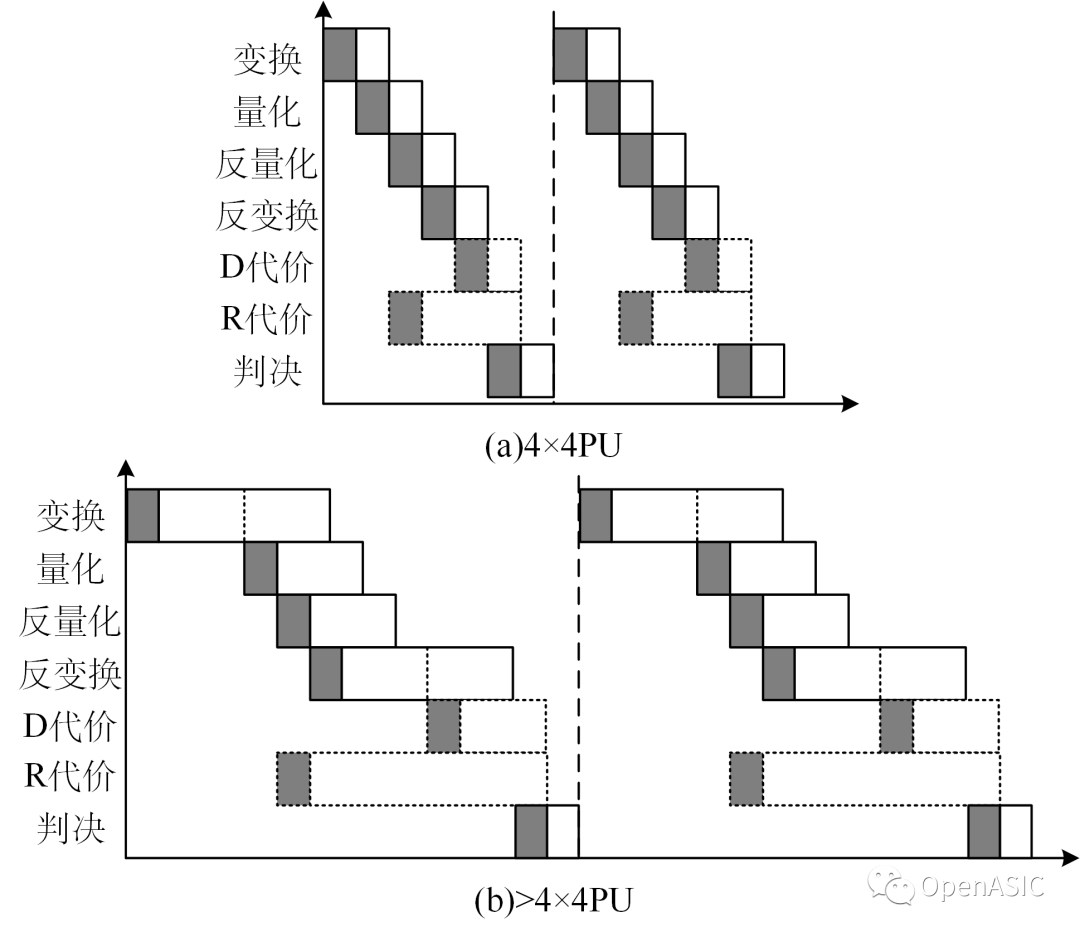
图9
代价计算模块如下图所示,主体为计算失真代价的dist模块和计算码率代价的rate模块,param模块提供算法中需要的参数信息。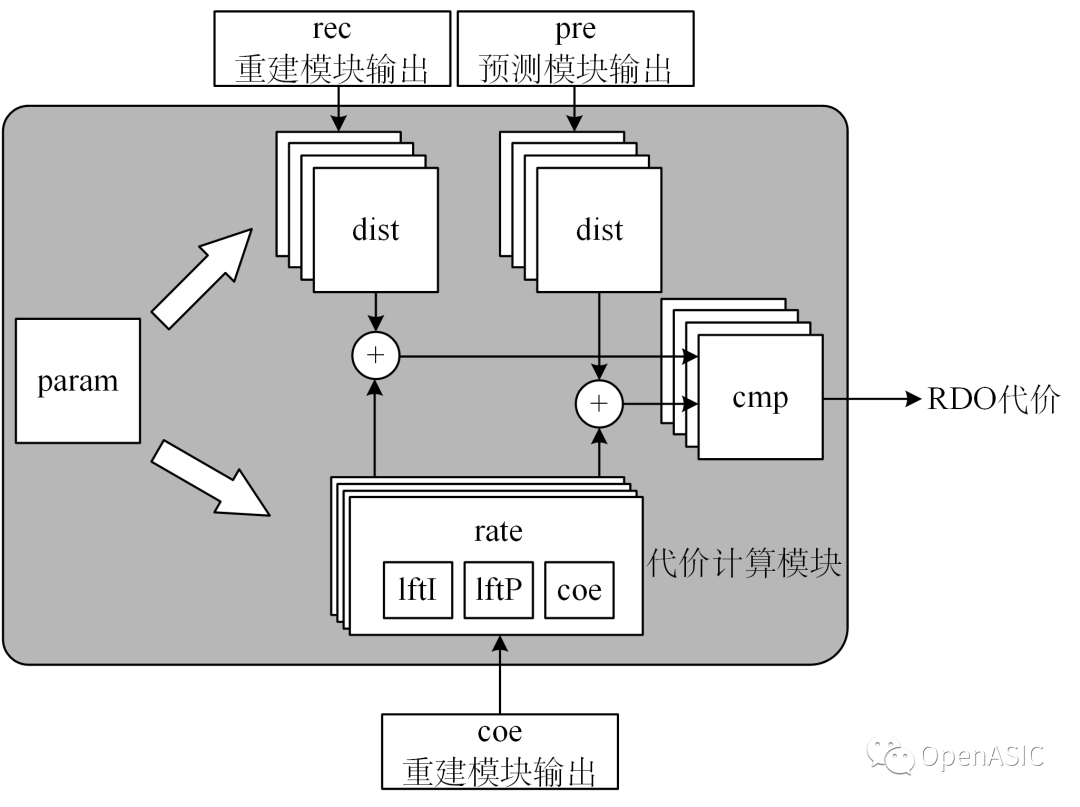
图10
对于失真代价(SSE)的计算,硬件中通过一组乘法器进行操作,可以在1cycle中完成且没有时序压力。对于码率代价的计算,本文的算法将其分为三个模块:lftI和lftP模块对应其余编码信息统计,coe模块对应变换系数编码信息统计,计算时序如下图所示。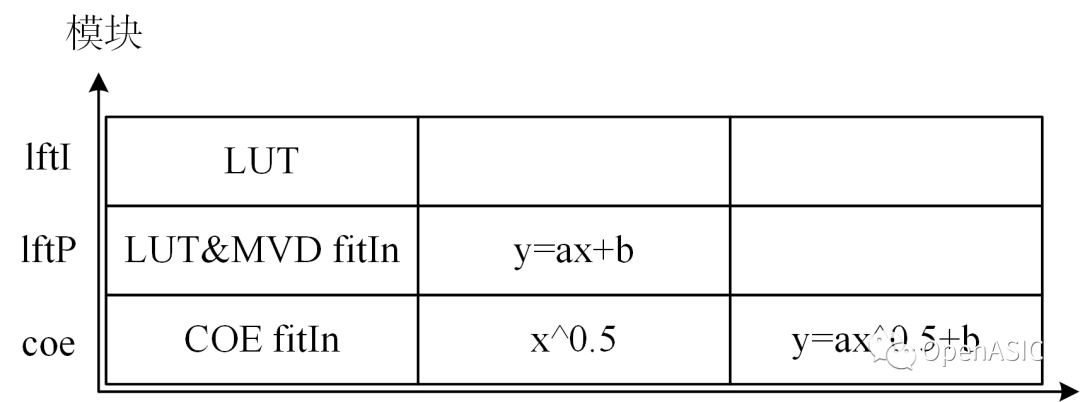
图11
param模块将放在配置寄存器中的参数和𝜆相乘得到新的参数,这种做法是为了省掉一个乘法步骤,优化时序。通常一个LCU中的配置信息是固定,在LCU编码开始,start信号使能时同时激活param模块,在数据到达代价计算模块前计算完成即可。
代价计算模块引入两组dist模块是为了计算Skip模式的率失真代价。Skip模式也是编码参数的一部分,所以在从代价计算模块到模式判决模块的数据传递过程中,会对任务发布模块通过FIFO传到模式判决模块的general mode进行覆写。
模式判决模块
模式判决模块的功能是根据代价计算模块输出的RDO代价对划分和模式进行判决,其流程框图如下图所示。其工作流程如下:mod模块收集当前PU所有遍历模式的亮度和色度分量的RDO cost,并从中选出当前PU代价最小的编码模式。当前四叉子树的母节点和子节点的率失真代价都计算完毕之后,对当前子树所在的块进行判决。
图12
整体上来看硬件RDO的遍历思路是尺寸从小到大、深度由深到浅进行的。Buffer会暂存所有层级的最右列和最下行的编码模式信息和重建像素。遍历过程中,在确定了四叉子树的最优模式和划分后,将对应的模式和重建像素从对应层级的Buffer中取出来,feedback到前级。
性能评估
采用global foundry 28nm工艺在500M下进行综合,得到RDO各模块的资源代价如下表所示。
表5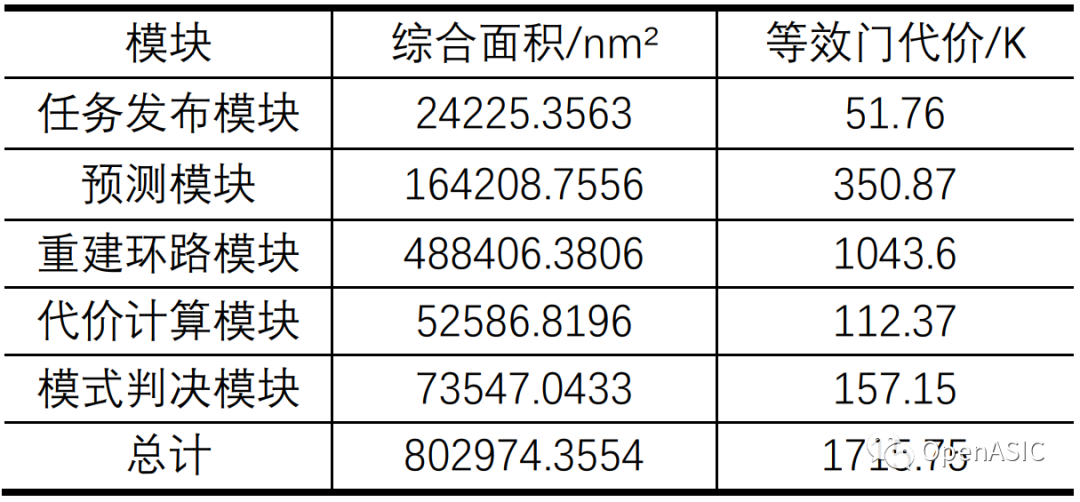
本文提出的码率估计算法VLSI实现(代价计算模块)和其他基于统计方法的码率估计算法VLSI实现对比如下表所示。增加非系数编码信息码率估计在rate计算模块引入了较多LUT,但对RDO整体来说面积不大,在大大降低了周期和时序压力的基础上,将BD rate缩小了近一倍。
表6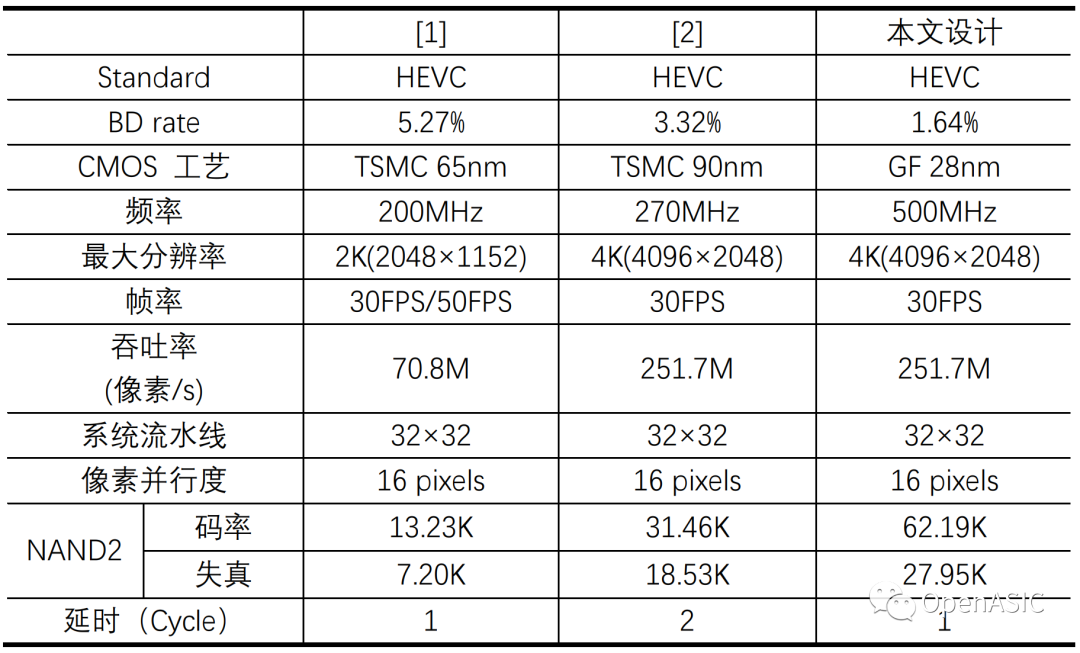
参考文献:
[1]Weiwei Shen, Yibo Fan, Leilei Huang.A Hardware-friendly method forrate-distortion optimization of HEVC intra coding[A].Technical Papers of 2014International Symposium on VLSI Design, Automation and Test. IEEE[C].IEEE,2014:1-4.
[2]Chang J H,Chang T S.Fast rate distortion optimization design for HEVC intra coding[A].2015IEEE International Conference on Digital Signal Processing[C].IEEE,2015:473-476.